Το competitive analysis στο digital marketing συχνά ξεκινά με ένα one-off, technical audit του website ενός ανταγωνιστή.
Εργαλεία όπως το Screaming Frog έχουν καθιερωθεί ως ο ηγέτης του κλάδου για τέτοιες αναλύσεις, επιτρέποντας στους SEO professionals να εντοπίζουν γρήγορα τεχνικά ζητήματα, όπως broken links (404s), server errors, redirections, duplicate content και προβλήματα με page titles και meta descriptions.
Ωστόσο, ένα one-off technical audit, ενώ είναι αναμφίβολα χρήσιμο, προσφέρει μόνο ένα snapshot της κατάστασης.
Είναι σαν μια φωτογραφία: αποτυπώνει το τι συνέβαινε τη συγκεκριμένη στιγμή, αλλά δεν αποκαλύπτει τη δυναμική, την εξέλιξη ή τις τάσεις που διαμορφώνουν την απόδοση του ανταγωνιστή με την πάροδο του χρόνου.
Η πραγματική αξία του Screaming Frog δεν περιορίζεται στην απλή εκτέλεση crawls και ελέγχων, αλλά έγκειται στην ικανότητά του να μετατραπεί από ένα εργαλείο one-off αναλύσεων σε ένα ισχυρό εργαλείο συνεχούς συλλογής δεδομένων για competition intelligence.
Αυτή η μεταμόρφωση επιτυγχάνεται μέσω της αυτοματοποίησης και της συστηματικής αποθήκευσης των δεδομένων.
Ενώ άλλα εργαλεία όπως το Semrush προσφέρουν ιστορικά δεδομένα για τις θέσεις κατάταξης και τις λέξεις-κλειδιά, τα οποία συλλέγονται εξωτερικά από τις σελίδες αποτελεσμάτων των μηχανών αναζήτησης (SERPs) , το Screaming Frog παρέχει τη δυνατότητα να συλλέξεις τα δικά σου, δομημένα, τεχνικά δεδομένα απευθείας από το website του ανταγωνιστή.
Η ικανότητα να συγκεντρώνεις δεδομένα για την αρχιτεκτονική του website, το περιεχόμενο και τα τεχνικά στοιχεία σε τακτική βάση, γεφυρώνει το κενό που υπάρχει με τα γενικής χρήσης εργαλεία και παρέχει μια βαθύτερη, πιο τεχνική εικόνα των ενεργειών του ανταγωνιστή.
Η στρατηγική αξία των ιστορικών δεδομένων
Η συστηματική και αυτοματοποιημένη συλλογή τεχνικών δεδομένων μέσω επαναλαμβανόμενων crawls είναι το κλειδί για την υιοθέτηση μιας προληπτικής στρατηγικής SEO.
Αυτή η διαδικασία, που συχνά αναφέρεται ως “SEO Forecasting,” μετατρέπει τον SEO professional από έναν διαχειριστή προβλημάτων (reactive handling) σε έναν στρατηγικό αναλυτή που μπορεί να προβλέψει αλλαγές και να τις αντιμετωπίσει έγκαιρα (proactive handling).
Τα ιστορικά δεδομένα επιτρέπουν την:
- Κατανόηση της μεταβλητότητας: Η παρακολούθηση on-page αλλαγών στους ανταγωνιστές, όπως τροποποιήσεις σε τίτλους σελίδων, περιγραφές ή τον αριθμό των λέξεων σε μια περιγραφή προϊόντος, μπορεί να αποκαλύψει αν αυτές οι ενέργειες είναι σποραδικές ή μέρος μιας καλά μελετημένης, μακροπρόθεσμης στρατηγικής.
- Πρόβλεψη επερχόμενων απειλών: Η ανίχνευση νέων URLs, η προσθήκη νέων φακέλων στη δομή του website ή το restructure του περιεχομένου μπορεί να αποτελέσει ένα προειδοποιητικό σήμα για επερχόμενες στρατηγικές του ανταγωνιστή, δίνοντας τον απαραίτητο χρόνο για την προετοιμασία μιας απάντησης.
- Ανίχνευση επιδράσεων αλγοριθμικών αλλαγών: Μια ξαφνική πτώση στην κατάταξη των keywords (που θα εντοπιστεί από ένα εργαλείο όπως το Semrush) μπορεί να εξηγηθεί από τεχνικά ευρήματα, όπως η μαζική προσθήκη noindex tags που θα αποκαλυφθεί από έναν αυτοματοποιημένο crawl. Η συσχέτιση των εξωτερικών δεδομένων από τις SERPs με τα εσωτερικά τεχνικά δεδομένα από το crawl προσφέρει μια πολύ πιο ολοκληρωμένη εικόνα της απόδοσης.
Ένα πλήρες pipeline και ο αναλυτικός οδηγός
Αυτός ο οδηγός θα παρουσιάσει μια ολοκληρωμένη διαδικασία, από την προετοιμασία έως την ανάλυση, δομημένη ως ένα πλήρες pipeline.
Θα ξεκινήσουμε με την προσαρμογή του Screaming Frog, θα προχωρήσουμε στην αυτοματοποίηση της εκτέλεσης και της αποθήκευσης των δεδομένων στο cloud, και θα καταλήξουμε στην αξιοποίησή τους για τη δημιουργία ουσιαστικών reports και στρατηγικών αποφάσεων.
Αυτή η προσέγγιση καθιστά σαφές ότι η τελική αξία δεν είναι μια απλή εντολή, αλλά ένα ολοκληρωμένο, αυτοματοποιημένο σύστημα.
Step #1: Screaming Frog setup για competitive crawling
Πριν ξεκινήσει οποιαδήποτε τεχνική διαδικασία, είναι απαραίτητο να επιλεγεί ο κατάλληλος ανταγωνιστής.
Η στόχευση σε έναν ανταγωνιστή που δεν είναι πραγματικά σημαντικός μπορεί να οδηγήσει σε άχρηστα δεδομένα.
Προτείνουμε να εστιάσεις σε 2-3 ανταγωνιστές που πληρούν συγκεκριμένα κριτήρια :
- Market Overlap: Προσφέρουν παρόμοια προϊόντα ή υπηρεσίες και απευθύνονται στο ίδιο κοινό.
- Search Visibility: Κατατάσσονται καλά για τις ίδιες λέξεις-κλειδιά που σε ενδιαφέρουν.
- Website Size: Έχουν παρόμοιο μέγεθος με το δικό σου website, ώστε η ανάλυση να είναι ουσιαστική.
Αφού επιλεγεί ο στόχος, είναι κρίσιμο να ρυθμίσεις το Screaming Frog για να συλλέξει τα σωστά δεδομένα.
Προσαρμογή των Ρυθμίσεων του Crawl (Configuration)
Ενώ το Screaming Frog είναι ρυθμισμένο εξ ορισμού να συμπεριφέρεται παρόμοια με το Googlebot, η αξία του στο competitive analysis δεν είναι τα default settings, αλλά το customization.
Η επιλογή των σωστών ρυθμίσεων μετατρέπει το εργαλείο από έναν γενικό crawler σε έναν εξειδικευμένο data collector.
- Crawl Limits: Για να διαχειριστείς την πολυπλοκότητα και τον όγκο των δεδομένων, είναι σημαντικό να καθορίσεις τα crawl limits. Συνιστάται να ξεκινήσεις με depth τουλάχιστον 5 επιπέδων (levels deep) για να εξασφαλίσεις μια περιεκτική ανάλυση. Άλλες σημαντικές ρυθμίσεις περιλαμβάνουν τον περιορισμό του συνολικού αριθμού των URLs ή του μέγιστου file depth.
- JavaScript Rendering: Πολλά σύγχρονα websites είναι κατασκευασμένα με δυναμικά frameworks όπως το Angular, το React και το Vue.js. Για να διασφαλίσεις ότι το Screaming Frog βλέπει τη σελίδα όπως ένας χρήστης ή μια μηχανή αναζήτησης, είναι κρίσιμο να ενεργοποιήσεις το JavaScript rendering στις ρυθμίσεις.
- Custom Extraction: Το Screaming Frog μπορεί να συλλέξει δεδομένα που δεν είναι μέρος του βασικού crawl. Χρησιμοποιώντας CSS Path, XPath ή regex, μπορείς να εξαγάγεις οποιαδήποτε πληροφορία από το HTML μιας σελίδας, όπως τιμές προϊόντων, κριτικές, SKU ή συγκεκριμένα social meta tags. Αυτή η δυνατότητα καθιστά το Screaming Frog ένα ισχυρό εργαλείο για στοχευμένη ανάλυση δεδομένων.
- User-Agent και Robots.txt: Η προσαρμογή του User-Agent ώστε να μιμείται το Googlebot και η σωστή διαχείριση του
robots.txtείναι απαραίτητα για την ακριβή προσομοίωση του πώς μια μηχανή αναζήτησης βλέπει το website του ανταγωνιστή.
Η ολοκλήρωση αυτών των ρυθμίσεων στην επιφάνεια εργασίας και η αποθήκευσή τους ως ένα setting file (.seospider.config) είναι το πρώτο κρίσιμο βήμα. Αυτό το αρχείο θα χρησιμοποιηθεί αργότερα για την αυτοματοποίηση της διαδικασίας.
Step #2: Αυτοματοποίηση του crawling μέσω της γραμμής εντολών (CLI)
Βασικές έννοιες της γραμμής εντολών (CLI)
Για να μετατρέψεις τη διαδικασία του crawling από manual σε automated, είναι απαραίτητη η χρήση της γραμμής εντολών (Command Line Interface, CLI). Η CLI επιτρέπει την εκτέλεση του Screaming Frog χωρίς το γραφικό περιβάλλον χρήστη (GUI), καθιστώντας την ιδανική για αυτοματοποιημένα scripts.
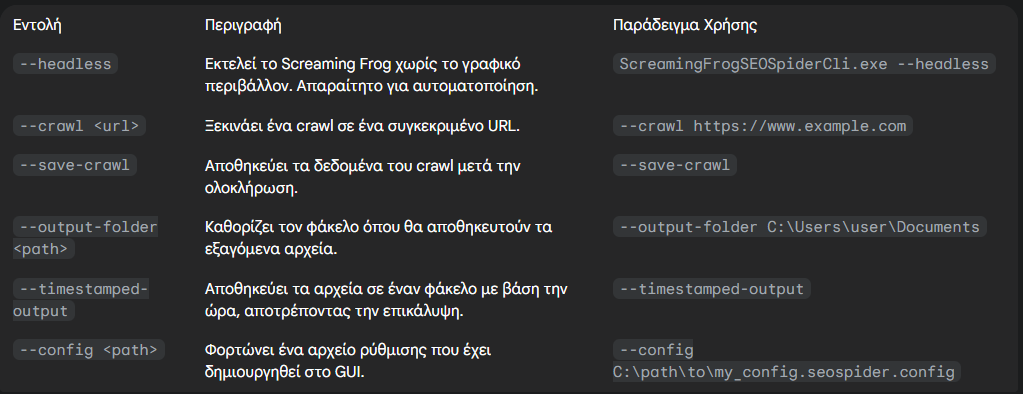
Screaming Frog CLI Commands
Το Screaming Frog παρέχει μια σειρά από εντολές που μπορούν να χρησιμοποιηθούν στη γραμμή εντολών. Ο παρακάτω πίνακας συνοψίζει τις πιο σημαντικές:
Δημιουργία και χρονοπρογραμματισμός των scripts
Η πραγματική αυτοματοποίηση επιτυγχάνεται με τη δημιουργία ενός script (όπως ένα αρχείο .bat για Windows ή ένα shell script για Linux/macOS) που συνδυάζει αυτές τις εντολές. Αυτό το script μπορεί να εκτελέσει το crawl χωρίς καμία χειροκίνητη παρέμβαση και να αποθηκεύσει τα αποτελέσματα σε έναν καθορισμένο φάκελο.
Παράδειγμα ενός απλού script
ScreamingFrogSEOSpiderCli.exe --headless --crawl https://competitor.com --config C:\path\to\my_config.seospider.config --save-crawl --output-folder C:\crawls --timestamped-outputΑυτή η εντολή θα εκτελέσει το crawl με τις προσαρμοσμένες ρυθμίσεις, θα το αποθηκεύσει αυτόματα και θα δημιουργήσει έναν φάκελο με timestamp για την αποθήκευση των αποτελεσμάτων.
Η δημιουργία ενός script μετατρέπει μια επαναλαμβανόμενη, χειροκίνητη διαδικασία σε ένα αυτοματοποιημένο task που μπορεί να προγραμματιστεί να εκτελείται σε προκαθορισμένα διαστήματα.
Αυτό μπορεί να γίνει με τη χρήση του Task Scheduler στα Windows ή του Cron στα Linux/macOS. Η δυνατότητα να εκτελείται αυτή η διαδικασία στο παρασκήνιο, ακόμη και σε έναν απομακρυσμένο διακομιστή, απελευθερώνει τον SEO expert για να εστιάσει στην ανάλυση, όχι στη συλλογή δεδομένων.
Step #3: Δημιουργία της Cloud υποδομής και του ETL Pipeline
Γιατί χρειαζόμαστε ένα transfer script;
Το Screaming Frog, ως desktop application, αποθηκεύει τα εξαγόμενα, crawled αρχεία τοπικά στον υπολογιστή όπου εκτελείται.
Δεν υπάρχει ενσωματωμένη εντολή για την άμεση μεταφόρτωση των δεδομένων σε ένα περιβάλλον cloud, όπως το Google Cloud Storage (GCS) ή το Amazon S3.
Αυτό δημιουργεί την ανάγκη για ένα ενδιάμεσο βήμα: ένα script, συνήθως γραμμένο σε Python, που θα λειτουργήσει ως αγωγός (pipeline), εντοπίζοντας το πιο πρόσφατο τοπικό αρχείο και μεταφορτώνοντάς το στο cloud.
Αυτή η διαδικασία είναι κρίσιμη, καθώς μετατρέπει τα δεδομένα από τοπικά αποθηκευμένα (“on-premise”) σε κατανεμημένα στο cloud, καθιστώντας τα προσβάσιμα από οπουδήποτε για περαιτέρω ανάλυση και διατηρώντας ιστορικότητα χωρίς να καταλαμβάνεται χώρος στον τοπικό δίσκο.
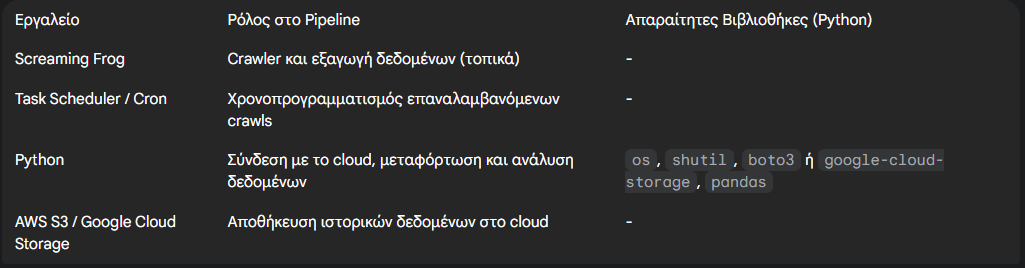
Επιλογή Cloud πλατφόρμας (AWS S3 vs. Google Cloud Storage)
Δύο από τις πιο δημοφιλείς επιλογές για την αποθήκευση δεδομένων στο cloud είναι το Amazon S3 και το Google Cloud Storage.
Η διαδικασία μεταφόρτωσης είναι παρόμοια και στις δύο πλατφόρμες, καθώς και οι δύο προσφέρουν Python SDKs για την προγραμματική διαχείριση των αρχείων.
Α. Google Cloud Storage (GCS):
Για να συνδεθείς με το GCS, είναι απαραίτητο να εγκαταστήσεις τη βιβλιοθήκη google-cloud-storage με την εντολή pip install google-cloud-storage. Η αυθεντικοποίηση μπορεί να γίνει εύκολα μέσω του gcloud CLI. Αφού ρυθμιστούν τα credentials, το Python script μπορεί να χρησιμοποιήσει την StorageClient για τη μεταφόρτωση αρχείων.
Β. Amazon S3:
Για το AWS, η αντίστοιχη βιβλιοθήκη είναι η boto3, η επίσημη Python SDK. Η εγκατάσταση γίνεται με την εντολή pip install boto3. Η βιβλιοθήκη παρέχει δύο βασικές μεθόδους για τη μεταφόρτωση αρχείων: upload_file (για τοπικά αρχεία) και upload_fileobj (για αντικείμενα τύπου file-like). Και οι δύο μέθοδοι μπορούν να χειριστούν μεγάλα αρχεία, χωρίζοντάς τα αυτόματα σε μικρότερα τμήματα και μεταφορτώνοντάς τα παράλληλα.
Python Script και σχετικές ρυθμίσεις
Ανεξάρτητα από την πλατφόρμα που θα επιλεγεί, ο πυρήνας του Python script παραμένει ο ίδιος. Το script θα πρέπει να εκτελεί τα εξής βήματα:
- Εντοπισμός φακέλου: Να εντοπίζει τον φάκελο στον τοπικό δίσκο όπου το Screaming Frog αποθηκεύει τα αρχεία του crawl.
- Εύρεση του πιο πρόσφατου αρχείου: Δεδομένου ότι το Screaming Frog αποθηκεύει τα αρχεία με timestamp, το script μπορεί να σαρώσει τον φάκελο και να βρει το πιο πρόσφατο αρχείο βάσει της ημερομηνίας και ώρας δημιουργίας του.
- Μεταφόρτωση στο Cloud: Να χρησιμοποιεί το αντίστοιχο SDK (boto3 ή google-cloud-storage) για να μεταφορτώσει αυτό το αρχείο στον καθορισμένο bucket.
Αυτό το απλό script ολοκληρώνει το pipeline, εξασφαλίζοντας ότι τα δεδομένα του crawl μεταφέρονται αυτόματα από τον τοπικό υπολογιστή σε ένα ασφαλές και προσβάσιμο περιβάλλον cloud.
Step #4: Από τα δεδομένα στα insights: Ανάλυση με Python/Pandas
Το Screaming Frog για crawls comparison
Το Screaming Frog προσφέρει μια ενσωματωμένη λειτουργία σύγκρισης των crawls, η οποία επιτρέπει τη γρήγορη ανάλυση των αλλαγών μεταξύ δύο crawls.
Με τη χρήση αυτής της λειτουργίας, μπορεί κανείς να παρακολουθήσει την πρόοδο των τεχνικών ζητημάτων στο SEO και να εντοπίσει αλλαγές σε βασικά στοιχεία.
Μπορείς να επιλέξεις δύο crawls από το μενού του εργαλείου, να ρυθμίσεις τι ακριβώς θέλεις να συγκρίνεις (π.χ. page titles, code status) και να δείς τα αποτελέσματα στο tab “Change Detection”.
Η δύναμη της Python και του Pandas
Ενώ η ενσωματωμένη λειτουργία είναι χρήσιμη για γρήγορες συγκρίσεις, για πραγματικά βαθιά, ιστορική ανάλυση μεγάλων συνόλων δεδομένων, η χρήση της Python με τη βιβλιοθήκη pandas είναι απαραίτητη.
Τα αρχεία CSV που εξάγονται από το Screaming Frog είναι “raw” δεδομένα. Η χρήση του pandas επιτρέπει την αποτελεσματική επεξεργασία και μετατροπή αυτών των δεδομένων, επιτρέποντας τα εξής:
- Data Cleaning: Αφαίρεση περιττών στηλών, διόρθωση ονομάτων κεφαλίδων (π.χ., αντικατάσταση κενών με underscores) και αφαίρεση διπλότυπων εγγραφών.
- Merging: Η συγχώνευση (merge) δεδομένων από crawls διαφορετικών ημερομηνιών (pd.merge) είναι μια κρίσιμη λειτουργία που επιτρέπει την ανάλυση των αλλαγών με την πάροδο του χρόνου.

Παραδείγματα αναλύσεων και στρατηγικών εφαρμογών
Η χρήση του pandas μετατρέπει την επεξεργασία δεδομένων σε μια γρήγορη και επαναλαμβανόμενη διαδικασία.
Case Study: Αναλυτικά όλα τα βήματα
Για τις ανάγκες του παραδείγματος, ας υποθέσουμε ότι είσαι ο SEO Manager της dummy εταιρείας mybrand.gr.
Έχεις εντοπίσει δύο βασικούς ανταγωνιστές, την competitor-a.gr και την competitor-b.gr, και ο στόχος σας είναι να αυτοματοποιήσεις μια εβδομαδιαία ανάλυση της competitor-a.gr, αποθηκεύοντας τα δεδομένα σε ένα ασφαλές cloud περιβάλλον.
Βήμα 1: Ρύθμιση του Screaming Frog
Πριν από την αυτοματοποίηση, πρέπει να ρυθμίσεις το crawl με τις επιθυμητές παραμέτρους στο γραφικό περιβάλλον (GUI) του Screaming Frog. Αυτό διασφαλίζει ότι το script θα συλλέξει τα σωστά δεδομένα.
1. Εισαγωγή URL: Άνοιξε το Screaming Frog και τοποθέτησε το URL του ανταγωνιστή: https://www.competitor-a.gr.
2. Crawl Settings: Πλοηγήσου στο Configuration > Spider και ρύθμισε τις παραμέτρους.
3. Rendering: Στην καρτέλα Rendering, επίλεξε JavaScript για να εξασφαλίσεις ότι το Screaming Frog θα επεξεργαστεί τις σελίδες όπως ακριβώς τις βλέπουν οι μηχανές αναζήτησης.
4. Custom Extraction: Για να συλλέξεις ειδικά δεδομένα, όπως τιμές προϊόντων ή συγκεκριμένα social meta tags, χρησιμοποιήσε το Configuration > Custom > Extraction. Μπορείς να ορίσεις κανόνες με CSS Path, XPath ή regex.
5. Αποθήκευση των settings: Αφού ολοκληρώσεις τις ρυθμίσεις, αποθήκευσε το αρχείο με τα settings. Πήγαινε στο File > Configuration > Save As και αποθήκευσε το αρχείο με όνομα, π.χ., competitor_a_crawl.seospider.config.
Βήμα 2: Αυτοματοποίηση του Crawling μέσω της γραμμής εντολών
Το Screaming Frog μπορεί να εκτελεστεί χωρίς γραφικό περιβάλλον (headless mode) χρησιμοποιώντας τη γραμμή εντολών (CLI), γεγονός που είναι ιδανικό για την αυτοματοποίηση.
1. Δημιουργία Scripts: Δημιούργησε ένα απλό text file (π.χ. run_crawl.bat για Windows ή run_crawl.sh για Linux/macOS) με τις παρακάτω εντολές :
Για Windows (.bat):
cd "C:\Program Files (x86)\Screaming Frog SEO Spider"
ScreamingFrogSEOSpiderCli.exe --headless ^
--crawl https://www.competitor-a.gr ^
--config "C:\Users\YourUsername\Documents\competitor_a_crawl.seospider.config" ^
--save-crawl ^
--output-folder "C:\Users\YourUsername\ScreamingFrogCrawls" ^
--timestamped-outputcd "C:\Program Files (x86)\Screaming Frog SEO Spider": Πλοήγηση στον κατάλογο εγκατάστασης.
--headless: Εκτελεί το εργαλείο χωρίς GUI.
--crawl <url>: Ξεκινάει ένα crawl στο καθορισμένο URL.
--config <path>: Φορτώνει το αρχείο ρύθμισης που αποθήκευσες στο προηγούμενο βήμα.
--save-crawl: Αποθηκεύει το crawl μόλις ολοκληρωθεί.
--output-folder <path>: Ορίζει τον φάκελο εξόδου.
--timestamped-output: Δημιουργεί έναν φάκελο με βάση την τρέχουσα ημερομηνία και ώρα, αποτρέποντας την επικάλυψη των αρχείων.
2. Χρονοπρογραμματισμός (Scheduling): Μπορείς να χρησιμοποιήσεις το Task Scheduler των Windows ή το Cron του Linux για να εκτελείς αυτόματα το script σε εβδομαδιαία βάση.
Βήμα 3: Αυτόματo upload στο Cloud (Google Cloud Storage)
Δεν υπάρχει ενσωματωμένη λειτουργία για το uploading στο cloud, οπότε θα χρησιμοποιήσουμε ένα script σε Python. Αυτό το script θα βρει το πιο πρόσφατο αρχείο crawl και θα το μεταφέρει στον κατάλληλο bucket του Google Cloud Storage (GCS).
1. Εγκατάσταση Βιβλιοθηκών: Βεβαιώσου ότι έχεις εγκαταστήσει την επίσημη βιβλιοθήκη της Google:
Bash
pip install google-cloud-storage2. Authentication: Πρέπει να συνδεθείς με τον λογαριασμό σου στο Google Cloud. Ο πιο απλός τρόπος είναι να χρησιμοποιήσεις το gcloud CLI και να εκτελέσεις την εντολή:
Bash
gcloud auth application-default loginΑυτή η εντολή θα δημιουργήσει τα κατάλληλα credentials για να χρησιμοποιήσει το Python script.
3. Δημιουργία Python Script: Δημιούργησε ένα αρχείο (π.χ. upload_to_gcs.py) και επικόλλησε τον παρακάτω κώδικα:
import os
from google.cloud import storage
# ----- Παράμετροι -----
LOCAL_CRAWLS_FOLDER = "C:\\Users\\YourUsername\\ScreamingFrogCrawls"
GCS_BUCKET_NAME = "my-brand-competitor-crawls" # Αντικατέστησε με το όνομα του bucket σου
def find_latest_crawl_folder(base_folder):
"""Εντοπίζει τον πιο πρόσφατο φάκελο crawl βάσει της ημερομηνίας δημιουργίας."""
list_of_folders = [
os.path.join(base_folder, d)
for d in os.listdir(base_folder)
if os.path.isdir(os.path.join(base_folder, d))
]
if not list_of_folders:
return None
latest_folder = max(list_of_folders, key=os.path.getmtime)
return latest_folder
def upload_to_gcs(source_file_name, destination_blob_name, bucket_name):
"""Μεταφορτώνει ένα αρχείο σε ένα bucket του GCS."""
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(destination_blob_name)
blob.upload_from_filename(source_file_name)
print(f"File {source_file_name} uploaded to {destination_blob_name} in bucket {bucket_name}.")
if __name__ == "__main__":
latest_crawl_folder = find_latest_crawl_folder(LOCAL_CRAWLS_FOLDER)
if latest_crawl_folder:
print(f"Found latest crawl folder: {latest_crawl_folder}")
# Ανεβάζει όλα τα αρχεία του φάκελου
for file_name in os.listdir(latest_crawl_folder):
local_file_path = os.path.join(latest_crawl_folder, file_name)
# Δημιουργεί ένα μοναδικό όνομα για το αρχείο στο GCS
gcs_file_path = f"{os.path.basename(latest_crawl_folder)}/{file_name}"
upload_to_gcs(local_file_path, gcs_file_path, GCS_BUCKET_NAME)
else:
print(f"No crawl folders found in {LOCAL_CRAWLS_FOLDER}")Βήμα 4: Ολοκλήρωση και ανάλυση
Αφού τα δεδομένα έχουν αποθηκευτεί, η πραγματική αξία βρίσκεται στην ανάλυση.
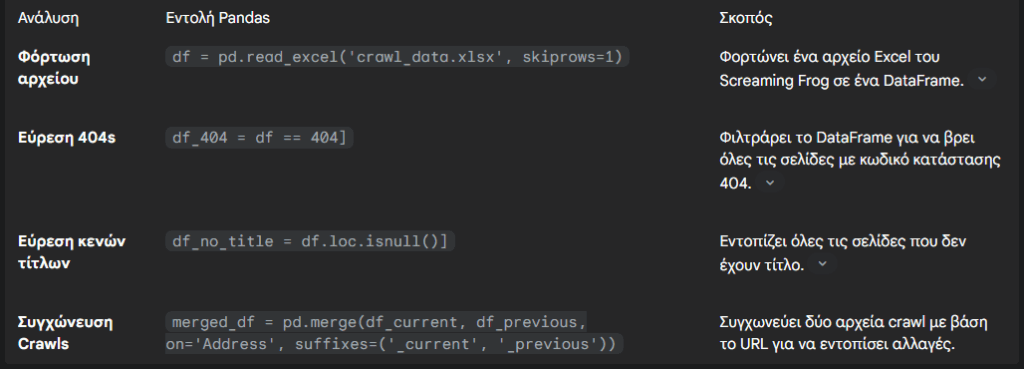
1. Φόρτωση Δεδομένων: Χρησιμοποίησε τη βιβλιοθήκη pandas για να αναλύσεις τα δεδομένα. Μπορείς να φορτώσεις τα εξαγόμενα αρχεία Excel ή CSV από το Screaming Frog.
import pandas as pd
# Τοποθεσία αρχείου στο GCS
gcs_path = "gs://my-brand-competitor-crawls/competitor-a_2025-10-15_12-00-00/internal_all.xlsx"
# Φορτώνει το αρχείο Excel από το GCS σε ένα DataFrame
df = pd.read_excel(gcs_path, skiprows=1) # Το skiprows=1 είναι απαραίτητο για τα αρχεία του Screaming Frog [10]
# Εμφανίζει τις 100 πρώτες γραμμές
print(df.head(100))
# Βρίσκει όλες τις σελίδες με σφάλμα 404
df_404 = df == 404]
print(f"Found {len(df_404)} URLs with 404 error.")2. Ιστορική Ανάλυση: Μπορείς να συγχωνεύσεις (merge) δεδομένα από διαφορετικά crawls χρησιμοποιώντας το pandas για να εντοπίσεις αλλαγές με την πάροδο του χρόνου, όπως νέες σελίδες, αλλαγές σε τίτλους ή τη διαγραφή περιεχομένου.
Αυτή η προσέγγιση μετατρέπει μια one-off εργασία σε ένα επαναλαμβανόμενο, αυτοματοποιημένο σύστημα που παρέχει συνεχή δεδομένα για τη λήψη στρατηγικών αποφάσεων.
Συνοψίζοντας
Η διαδικασία που περιγράφεται σε αυτόν τον οδηγό, από την προετοιμασία έως την ανάλυση, μετατρέπει μια κουραστική, χειροκίνητη εργασία σε ένα πλήρως αυτοματοποιημένο σύστημα. Το pipeline λειτουργεί στο παρασκήνιο, συλλέγοντας και αποθηκεύοντας τα δεδομένα, ενώ ο SEO expert απελευθερώνεται για να εστιάσει στην ερμηνεία τους.
Η τελική αξία της αυτοματοποίησης δεν είναι απλώς η εξοικονόμηση χρόνου. Είναι η δυνατότητα να μεταβείς από έναν reactive ρόλο σε έναν ρόλο στρατηγικού και proactive consultant.
Η συνεχής παρακολούθηση on-page στοιχείων, η ανίχνευση νέων URLs και η κατανόηση της συμπεριφοράς του ανταγωνιστή επιτρέπει την έγκαιρη ανίχνευση ευκαιριών και απειλών.
Μπορείς να προβλέψεις αλλαγές, να προτείνεις προληπτικές ενέργειες και να ενισχύσεις την αξία σου στην ομάδα ή στον πελάτη.
Το τελικό βήμα είναι η ενσωμάτωση αυτών των ευρημάτων σε εύκολα και κατανοητά reports. Τα ιστορικά δεδομένα που είναι αποθηκευμένα στο cloud μπορούν να τροφοδοτήσουν dashboards σε εργαλεία όπως το Looker Studio (πρώην Data Studio), παρέχοντας μια συνεχή ροή πληροφοριών και οπτικοποιήσεων.
Αυτή η διαδικασία ολοκληρώνει τον κύκλο, μετατρέποντας τα τεχνικά δεδομένα σε ουσιαστικές στρατηγικές αποφάσεις, και επιβεβαιώνει ότι στην εποχή του digital growth, το proactiveness είναι το απόλυτο ανταγωνιστικό πλεονέκτημα.